Multimodal AI Lab
Dept. of AI, Ewha Womans University. Seoul, Korea.



Multimodal AI Lab @ EWHA (PI: Jiyoung Lee) focuses on developing robust and generalizable AI models that understand and generate information across multiple modalities—vision, language, and audio. Our research spans multimodal generation, large audiovisual/vision-language models, video understanding, 3D perception, and cross-modal grounding. We build multimodal systems that learn with minimal supervision and perform reliably in diverse, real-world settings. We aim to push the boundaries of multimodal learning and create AGI that is creative, effective, and efficient.
Recruiting Undergraduate Interns/ Graduate Students / Postdoctoral Researchers: We are looking for undergraduate interns, graduate students, and postdoctoral researchers to research with! If you are interested in doing cool multimodal learning research, please send your CV and GPA to .
News
| Jan 2026 | Two papers are accepted at ICASSP 2026! 🎉 |
|---|---|
| Aug 2025 | One paper is accepted at ICCV Workshop@Gen4AVC! 🎉 |
| Jul 2025 | One paper is accepted in International Journal of Computer Vision (IJCV) [Q1, IF:9.3]! 🎉 |
| Apr 2025 | Multimodal AI Lab @ EWHA website is now open! 👋 |
| Mar 2025 | Prof.Jiyoung Lee joins in Dept. of AI, Ewha Womans University 👋 |
| Feb 2025 | One paper is accepted at CVPR 2025! 🎉 |
| Dec 2024 | Prof.Jiyoung Lee presented at Postech AI day (topic: Read, Watch and Scream! Sound Generation from Text and Video). |
| Dec 2024 | Prof.Jiyoung Lee presented at HUST, Vietnam (topic: Audio Generation from Visual Contents). |
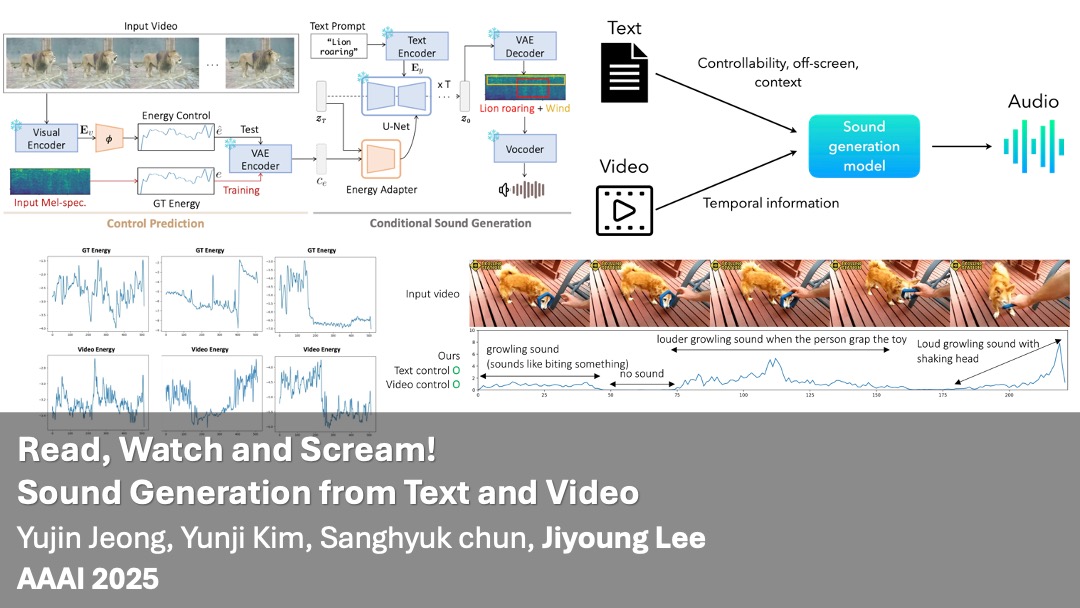
| Dec 2024 | One paper is accepted at AAAI 2025! 🎉 |
| Oct 2024 | One paper is accepted at NeurIPS 2024 Workshop on Video-Language Models 2024! 🎉 |
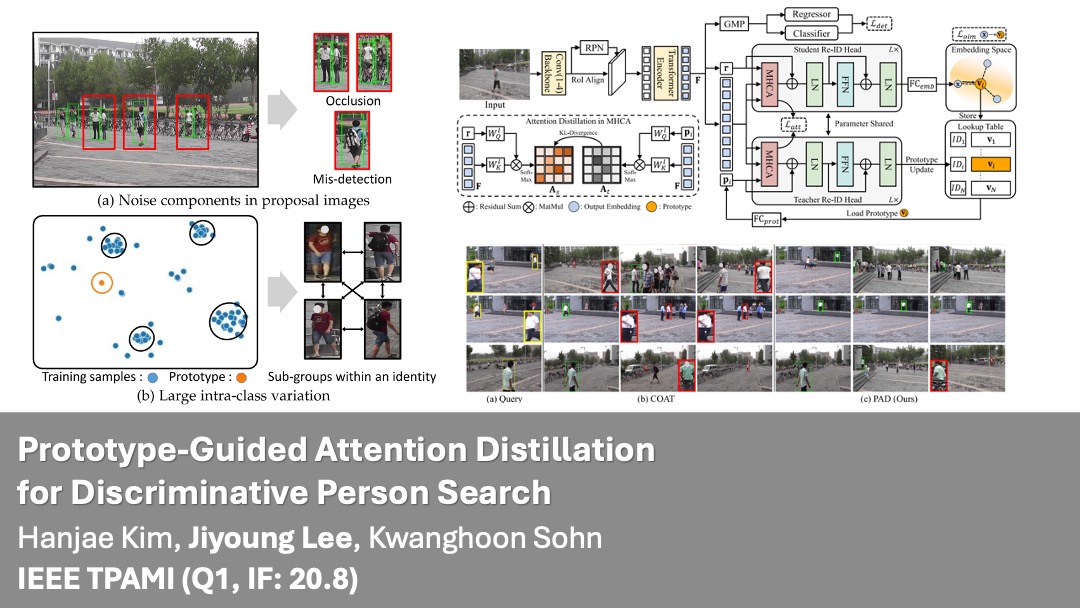
| Sep 2024 | One paper is accepted in IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) [Q1, IF:20.8]! 🎉 |
| Sep 2024 | Prof.Jiyoung Lee serves a lecture, Topics in Artificial Intelligence: Multimodal Deep Learning Theories and Applications, at Seoul National University (Fall 2024) |
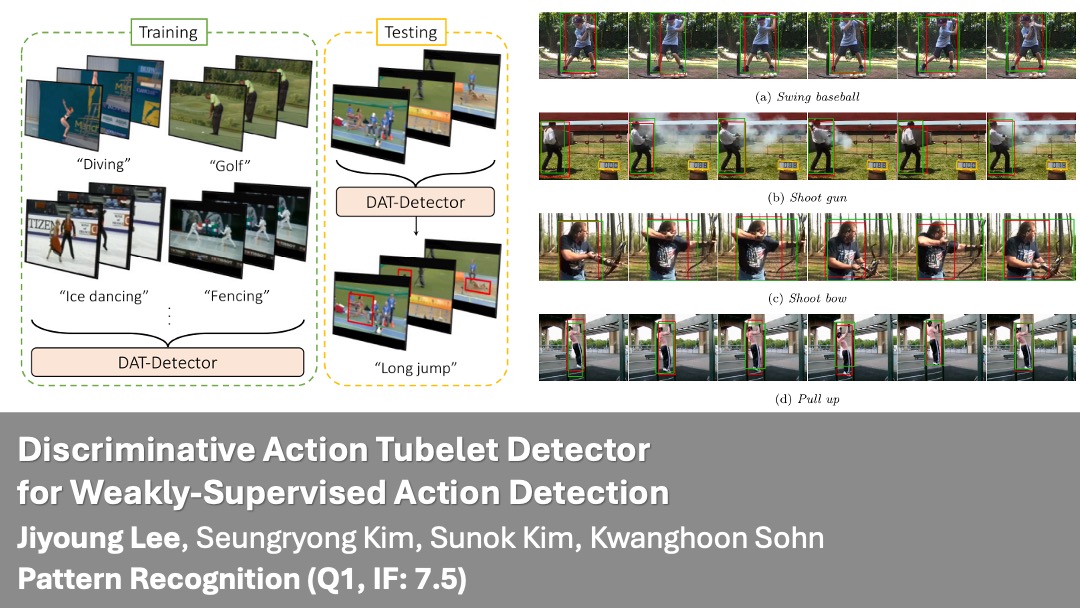
| Jun 2024 | One paper is accepted in Pattern Recognition (PR) [Q1, IF:7.5]! 🎉 |
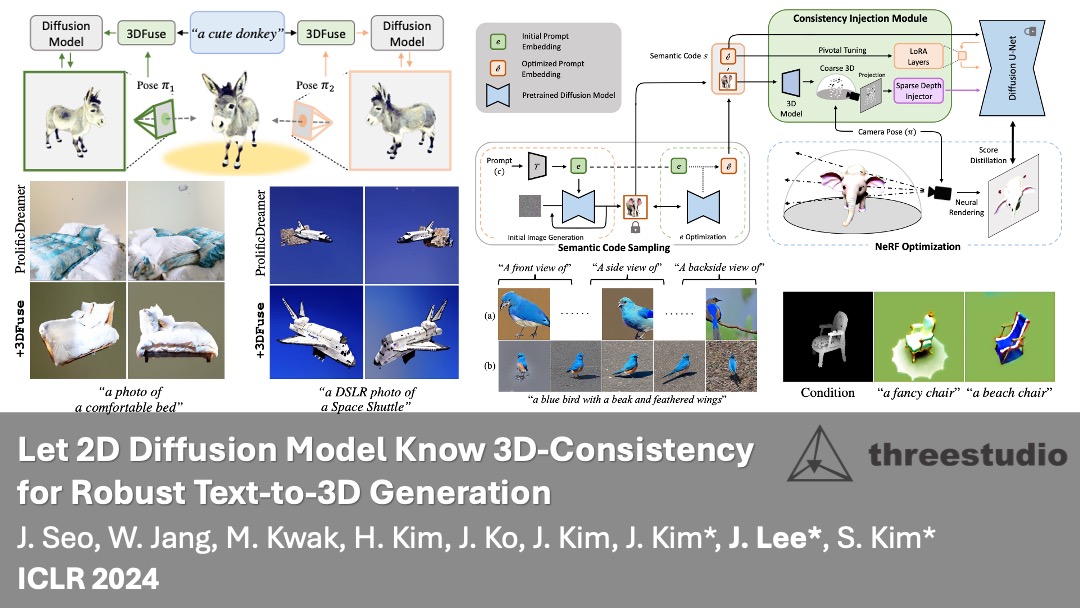
| Jan 2024 | Two papers are accepted at ICLR 2024! 🎉 |
| Before 2024 | You can find our older news in here |