Abstract
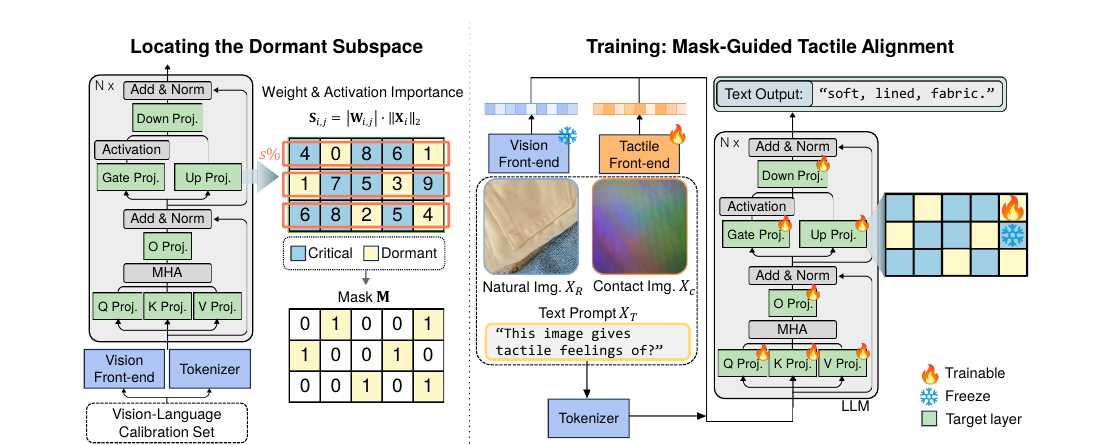
Touch supplies the physical grounding needed to perceive intrinsic material properties, such as friction and compliance, that vision alone often cannot resolve. Equipping multimodal large language models (MLLMs) with this tactile sense, alongside their pretrained vision-language ability, is a natural step toward reasoning about the physical world. In real-world deployment, however, doing so exposes a zero-sum trade-off: the limited parameter budget of compact models forces a choice between acquiring the new sensory modality and preserving the established vision-language reasoning. We present SPLASH, a mask-isolated tactile alignment learning framework for MLLMs. SPLASH quantifies the significance of each pretrained parameter and partitions the parameter space into a dormant and critical subspace. While the frozen critical subspace acts as a stable anchor to safeguard general visual knowledge, SPLASH updates the isolated dormant subspace to internalize tactile alignment towards LLMs. This mechanism effectively prevents catastrophic forgetting and ensures non-destructive modality expansion. Extensive experiments show that SPLASH achieves state-of-the-art performance on visuo-tactile benchmarks, including SSVTP, TVL, and TacQuad, while preserving its original general-purpose capabilities.
 Accepted to ECCV 2026
Accepted to ECCV 2026